NAACL 2022: Does Summary Evaluation Survive Translation?
I recently presented a paper at the NAACL 2022 conference for work conducted with my colleagues at Primer in collaboration with Technische Universität Berlin. At Primer, summarization is a core task that our platform performs daily, but summarization evaluation is quite challenging even in English. Since we are often presented with data from many languages, we explored whether summarization datasets could remain useful under translation, as resources for non-English languages are far less plentiful. I’ll outline some of the methods and findings of our research below.
Motivation
As I already hinted, it would be extremely useful if we could reuse English summarization datasets to evaluate similar models in other languages. Summary evaluation is a difficult task and has developed into a large field of its own. Typically we require a large dataset with reference texts, human and machine written summaries, and human evaluations of those summaries. It would be quite costly to perform the same data collection in many other languages. If we can simply reuse the texts and evaluations, advances in summarization could proliferate more quickly, especially to lower resource languages.
As a related question we might also ask: “how do we compare the performance of translation and summary evaluation?” Understanding the weaknesses of each technology can help focus efforts of future research.
Why is this problem difficult? For one, machine translation is far from perfect and the distortions it might introduce are not uniform across the texts. Translation may correct and simplify some texts, introduce errors into others, and push components of text quality like fluency, coherence, consistency, and relevance in different directions. Despite these known issues, the translation quality may still be high enough to maintain the usefulness of summarization datasets.
Approach
Dataset
To try to answer these questions, we focused on the SummEval dataset, which consists of 100 texts, each with 11 human written reference summaries and 17 machine generated summaries.
We fed all texts and summaries through Helsinki NLP Opus translation models, freely available on the HuggingFace model hub. Ultimately this produced 7 non-English copies of the dataset in French, German, Italian, Spanish, Afrikaans, Hindi, and Russian, languages chosen for their diversity in origins and relationships to English.
Evaluation Measures
We also explored a number of automated evaluation measures that lend themselves to multi-lingual tasks.
Reference free measures do not rely on the human written reference summaries and only require the reference text and machine generated summary. From this category, we experimented with Jensen-Shannon, ESTIME, and BLANC.
Reference-based measures rely on the overlap between the reference summaries and machine generated summaries. From this category we considered BLEU, BERTScore, and ROUGE 1,2, and L.
Results
Correlations
We first considered simple rank correlations between human and automated evaluations in English. The human experts evaluated summaries along four dimensions of quality: coherence, consistency, fluency, and relevance.
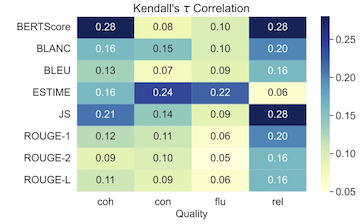
Generally correlations were low, though some automated measures stand out along particular lines of quality. We can see ESTIME, Jensen-Shannon, and BERTScore each excel in particular qualities, but none is dominant across all qualities. Despite the low correlations, these automated measures remain the standard for summary evaluation, and some research suggests that human evaluations are not an unblemished gold standard.
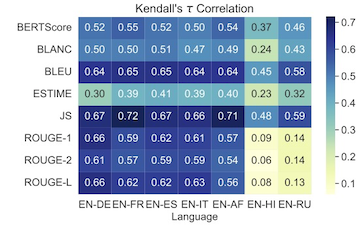
If instead we consider the correlations between an automated evaluation measure in English versus another language, we find much stronger correlations, especially in German, French, Spanish, Italian, and Afrikaans.
This result hints that translation may introduce less noise than already exists when comparing human and automated summary evaluations. To test this hypothesis more rigorously, we sought statistical tests to verify that correlations between expert scores and automated measures remain invariant under translation.
Statistical Tests
Statistical significance provides a quantitative criterion for whether an automated measure has “survived” translation. Even if automated measures are not perfect proxies for human judgment, we may consider them useful under translation if they score summaries in a consistent manner.
While traditional significance tests are meant to detect a difference between test statistics, we instead want to detect a lack of difference. We turn to equivalence testing, a testing paradigm that reverses traditional null and alternative hypotheses. The Two One Sided Tests, or TOST, method of equivalence testing requires setting a margin of equivalence, here $\Delta_E$, within which correlations are considered the same.
$$ H_0: \rho_1 - \rho_2 < -\Delta_E \text{ or } \rho_1 - \rho_2 > \Delta_E $$ $$ H_1: -\Delta_E < \rho_1 - \rho_2 < \Delta_E $$
When the absolute difference between two correlations lies within this margin, it is evidence for the alternative hypothesis. Unfortunately this presents a parameter that must be chosen by the experimenter, and we explore the impact of the margin choice on our conclusions.
We explored a range of equivalence margins to understand its impact on the significance of our results. We find that the choice of margin is indeed quite impactful on the number of equivalent results found. We focus on results using a margin tailored to each measure of quality, calculated as the standard deviation over measure-expert correlations. Below are the results of the signficance tests using the standard deviation margin. The blue squares indicate a significant result of equivalence while the red outlines indicate the result remained significant after the multiple testing correction.
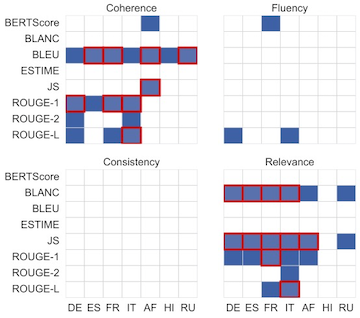
We find that the languages that are closer to English are more likely to preserve the relationship between automatic and human evaluation. Fluency and consistency appear more difficult to maintain under translation than coherence or relevance.
Qualitative Evaluation
We employ round trip translation to isolate the effects of translation noise, in which we translate the data to another language and then translate it again back to English.By returning each text to English, the performance of the summary evaluations should not be affected by language.
Therefore to isolate the effects of translation, we consider the shift in probability that one measure is better than another in bootstrapped samples under translation and round-trip translation.
Under forward translation, we see greater shifts in probability than when we return the text back to English. This is visually represented by the points that lie under the y=x line in the figure below.
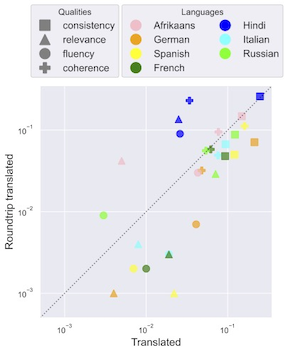
While the shifts for round-trip translations are on average smaller, they demonstrate that translation is far from perfect and introduces enough noise to be detected by the summarization evaluation measures. This analysis serves as a tool for quantitatively disentangling the effect of performing the evaluation in another language and the noise introduced by translation models.
Conclusions
We found that translation can preserve automatic evaluation measures along certain dimensions of summary quality, though there are clear differences in performance based on the choice of target language, automated measure, and notion of quality.
There is a lot of potential for future work to expand the utility of equivalence testing and probe the determinants of evaluation survival under translations. Our methods could also easily be extended beyond summarization evaluation. English is still a far more resourced language in NLP, and we present essential tools for accelerating their proliferation to other languages.
If interested, I invite you to read the full paper and review the code linked above.